- Products

- Developers
- User stories
- Blog
- Pricing

How to implement HTTP request retry policies
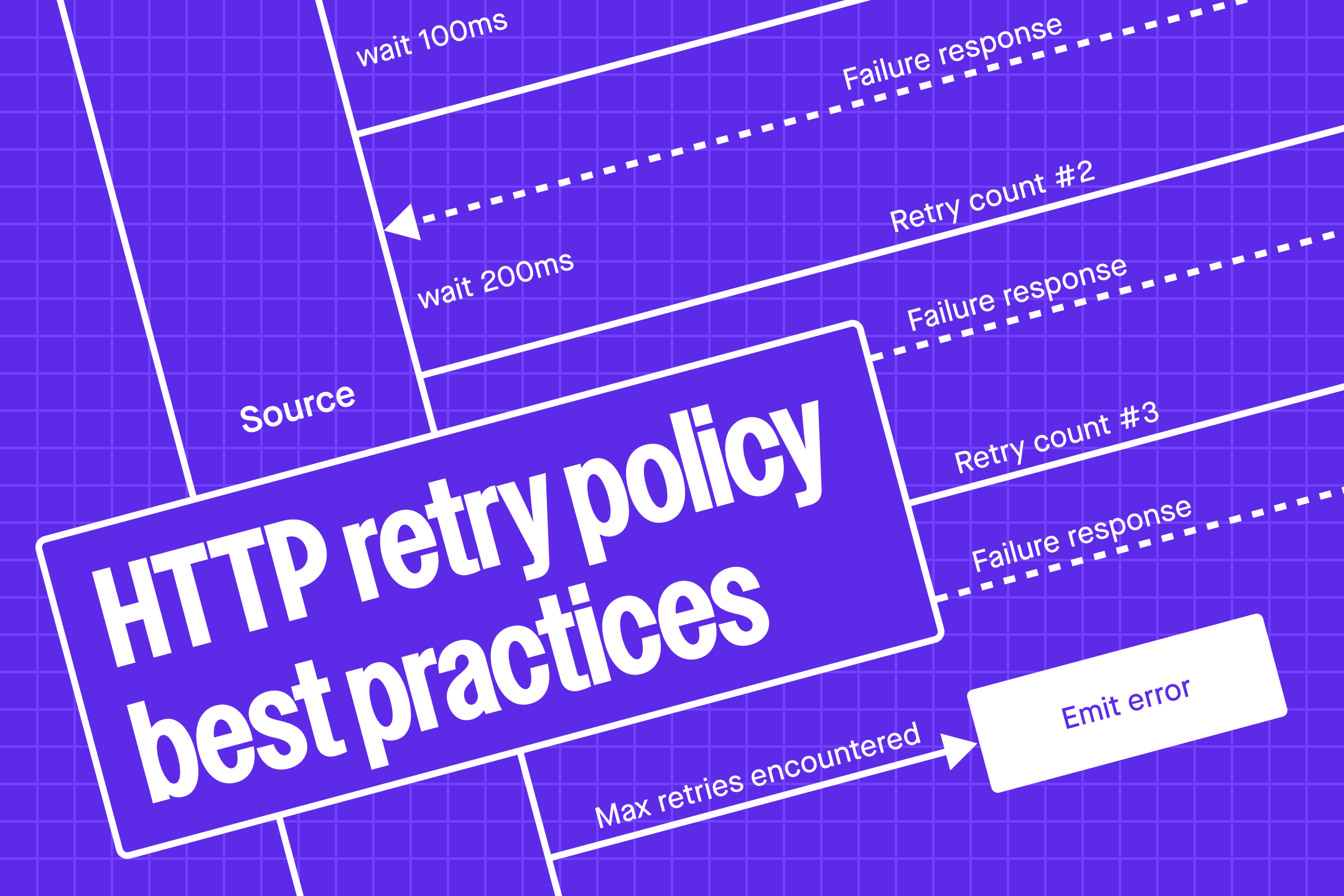
HTTP requests are always at risk of failure. No matter how highly available both the source and destination hosts are, the request can still encounter an issue in the intermediary network that you have no control over. Given this, it makes sense to devise an HTTP request retry strategy. You want to ensure systems can handle and recover from unexpected failures when making HTTP requests.
Introduction
HTTP requests are always at risk of failure. No matter how highly available both the source and destination hosts are, the request can still encounter an issue in the intermediary network that you have no control over.
Given this, it makes sense to devise an HTTP request retry strategy. You want to ensure systems can handle and recover from unexpected failures when making HTTP requests.
So, what are the best practices when implementing HTTP retry policies?
Writing resilient code to cover all what-ifs is just one part of the picture. What if the API doesn’t respond? What if the request times out? That’s where retry policies come in.
HTTP retry policy best practices
Often it makes sense to retry failed requests. For example, if it’s a transient error. This gives the request a second chance to complete and ensures your application can proceed as normal.
However:
Retrying every failed request immediately after failure can also be problematic. Imagine a scenario where you encounter a 100% failure rate.
Retrying every request in that scenario would increase the load on your server. It then has to process not only new requests but also retry the failed ones. Additionally, it can have a knock-on impact on the target service. This means flooding it with requests and increasing the load. Then in the end, it takes longer to recover from the initial failure.
Here’s one of the most common approaches we see by Pusher users:
Implementing an HTTP retry strategy using exponential backoff with max number of retry attempts.
Why use exponential backoff?
An exponential backoff strategy involves increasing the time that elapses between retries. It reduces the rate of requests and thereby protects against increased load. Reducing the rate of requests helps protect against an increased load on both the source and destination hosts. At the same time, it still allows new requests to be processed at a normal rate.
It’s called the exponential backoff strategy because retries will increase exponentially. For example, you might initially retry after 100 ms.Then if that request also fails, you would wait a further 200 ms, followed by a further 400 ms 800 ms, and so on.
Max backoff delay
Exponential backoff allows you to retry failed requests. Through it, you can give the root cause of the failure a chance (and time) to resolve itself. However, exponential backoff can quickly cause long delays between retries. That’s why it’s preferred to manage the maximum backoff between retry requests.
Let’s say you have an exponential backoff setup where you delay the first retry 1 second. This increases exponentially after each retry. After four retries, a total of 15 seconds has passed from the initial request. This is often an unacceptable delay.
To prevent this, it is commonplace to introduce a maximum delay between requests.
Going back to the previous scenario:
With the initial 1 second delay, we can reduce the total delay from 15 seconds to 7 seconds by adding a maximum delay of 2 seconds between retries.
Using maximum retry cap
The exponential backoff strategy allows you to safely retry requests. However, without proper management, you could potentially end up retrying requests indefinitely.
As such, it makes sense to attempt to track how many times the client tried to retry an individual request. This is to ensure that after a specific number of retries, the request is abandoned. This can then trigger some follow-up logic such as logging and alerting procedures. Or even a fallback to another method of delivering the data.
When to use exponential backoff and for how long?
The approach to HTTP retries is relatively standard. But the precise values used for the backoff strategy and the max number of retries often varies. It depends on the requirements of your application.
Let’s take high-volume, high-accuracy apps as an example. In this case, you need up-to-date information at all times. You can set up a retry to fire multiple times in short succession. Perhaps after 25, 50, 100, and 200 ms.
After the fourth attempt, if the request is still failing, you may discard the request. You know that your application will shortly process a new request, superseding the failed request.
What about lower volume use cases where the realtime experience is less critical? Let’s take order status dashboards as an example. You can retry after 1, 2, 4, and 6 seconds. The likelihood of a superseding event is low and your client can wait for a few seconds without significant impact.
What do you need to watch out for when constructing this retry strategy? With exponential backoff and max retry counts you should consider two things:
- what your application requires,
- what tolerances are available in terms of request delays and failures.
When not to retry HTTP requests
We’ve discussed when and how to implement a retry strategy but some use cases don’t require a strategy at all. For example, FX, crypto, stock trackers, betting and sports apps, and livestream activity.
If you have extremely high-volume situations, you may want to discard all failed requests. The server will process the next request in a very short time frame and it will reduce the impact of a single failed request.
Additionally, if the requests contain a full suite of data, then you may not need to retry any failed requests. Future requests will also include the data from the failed request. Retrying the request could be considered additional overhead that’s not required.
There are libraries available to help implement exponential backoff, for example for NodeJS or for PHP. These libraries will typically support max retry caps since that is also part of the best practice retry policy.
Although a HTTP request retry is not suitable for all scenarios, setting a robust strategy will add an extra layer of stability to your applications.
If you have any questions about HTTP retries in your Pusher app, you can reach out to our Support team.






© 2025 Pusher Ltd. All rights reserved.
Pusher Limited is a company registered in England and Wales (No. 07489873) whose registered office is at MessageBird UK Limited, 3 More London Riverside, 4th Floor, London, United Kingdom, SE1 2AQ.